프로젝트 2 - 모델 선정(한국어, 일본어, 속도 비교)
이 포스팅은 약 2달 전에 진행했던 내용이지만, 시간이 없었던 관계로 현재 업로드하였습니다.
1. 모델 후보 선정
LLM을 활용하는 데 있어 파라미터 수가 너무 클 경우 컴퓨팅 자원이 과도하게 필요하다는 문제가 있습니다. 또한 향후 온디바이스 환경에서도 동작할 수 있어야 하므로, 최대한 작은 크기인 3~4B 모델을 대상으로 후보를 선정하였습니다.
| 모델 | 특징 |
|---|---|
| naver-hyperclovax/HyperCLOVAX-SEED-Vision-Instruct-3B | 네이버의 최신 모델, 한국어 및 관광 정보 안내에 강점 |
| meta-llama/Llama-3.2-3B-Instruct | Meta의 오픈소스 모델, 뛰어난 다국어 성능 |
| Bllossom/llama-3.2-Korean-Bllossom-3B | Llama-3.2-3B를 한국어로 파인튜닝한 모델 |
| Gemma 3-4b-it | Google Gemma 최신 모델, 다국어 포함 뛰어난 성능 |
| Qwen/Qwen3-4B | Qwen 최신 모델, 뛰어난 다국어 성능 기대 |
2. 성능 및 속도 검증
일본인을 대상으로 한 관광 안내 서비스의 특성상 두 가지 검증이 필요했습니다.
- 한국어 및 일본어 성능 검증: 한국어 문서를 확인한 후 정확하게 일본어로 답변하기 위해 필수적인 능력이며, 일본인 관광객이 통역 과정에서 활용할 수 있기 때문입니다.
- 속도 검증: 온디바이스 환경을 고려하여 실사용 가능한 처리 속도를 확인합니다.
원래는 BLEU 등의 방법을 통해 통번역 성능을 검증하려 했으나, 소형 모델의 특성상 제대로 측정되지 않아 해당 부분은 스킵하였습니다.
(1) 한국어 성능 검증
mmlu_prox 데이터셋을 활용하여 한국어 MMLU 성능을 측정하였습니다.
(2) 일본어 성능 검증
mmlu_prox 데이터셋을 활용하여 일본어 MMLU 성능을 측정하였습니다.
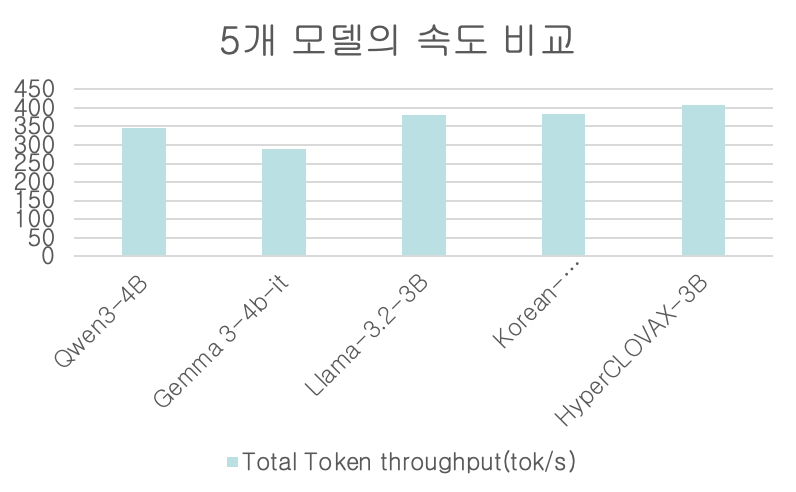
(3) 속도 성능 비교
vLLM의 벤치마크 스크립트를 활용하여 Total Token Throughput(tok/s)을 측정하였습니다.
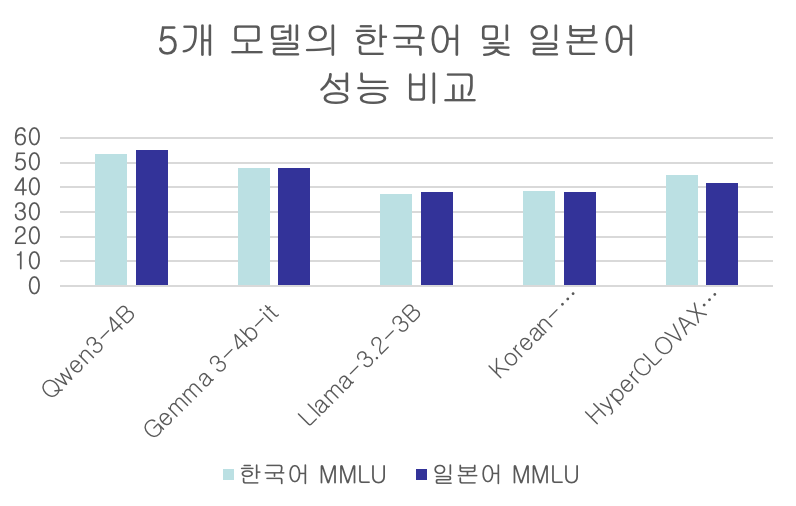
결론
속도 면에서는 3B 모델들보다 다소 떨어지는 부분이 존재하지만, 한국어 및 일본어 MMLU 성능이 압도적으로 우수하기 때문에 Qwen3-4B 모델을 최종 선정하였습니다.